1. 경로 저장시 DB 호출이 너무 많음
문제 발생
먼저 경로 저장시 너무 많은 DB 접근이 이뤄지는 것을 확인할 수 있었다.
경로 저장시 route, bound, road, guide 총 4개의 테이블에 저장을 해야하는데, 이상적인 DB 접근을 생각해보면 총 4번만 접근하면 된다.
하지만 지금은 너무 많은 접근이 이뤄지고 아래 코드를 보면 문제점을 금방 찾을 수 있다.
아래는 HistoryService의 saveHistory의 문제를 일으키는 부분이다.
for (KakaoRouteAllResponseDto.Section allSection : sections) {
KakaoRouteAllResponseDto.Road[] roads = allSection.getRoads();
KakaoRouteAllResponseDto.Guide[] guides = allSection.getGuides();
for (KakaoRouteAllResponseDto.Road roadDto : roads) {
String vertexesString = "";
vertexesString += Arrays.stream(roadDto.getVertexes()).mapToObj(String::valueOf).collect(Collectors.joining(" "));
Road roadEntity = new Road(vertexesString, route);
roadRepository.save(roadEntity);
}
for (KakaoRouteAllResponseDto.Guide guideDto : guides) {
String name = guideDto.getName();
double x = guideDto.getX();
double y = guideDto.getY();
int distance = guideDto.getDistance();
int duration = guideDto.getDuration();
int type = guideDto.getType();
String guidance = guideDto.getGuidance();
int roadIndex = guideDto.getRoadIndex();
Guide guideEntity = new Guide(name, x, y, distance, duration, type, guidance, roadIndex, route);
guideRepository.save(guideEntity);
}
}for문을 한번 순환할 때마다 DB에 접근하는 것을 볼 수 있다.
문제 해결 및 파생 문제 발생1
.save() 메서드를 사용하지 말고, .saveAll() 메서드를 사용해서 위 문제를 해결해 보겠다.
List<Road> roadList = new ArrayList<>();
List<Guide> guideList = new ArrayList<>();
// for문 돌면서 모든 Road의 vertexes를 vertexString에 띄어쓰기로 구분해서 넣어라
for (KakaoRouteAllResponseDto.Section allSection : sections) {
KakaoRouteAllResponseDto.Road[] roads = allSection.getRoads();
KakaoRouteAllResponseDto.Guide[] guides = allSection.getGuides();
for (KakaoRouteAllResponseDto.Road roadDto : roads) {
String vertexesString = "";
vertexesString += Arrays.stream(roadDto.getVertexes()).mapToObj(String::valueOf).collect(Collectors.joining(" "));
Road roadEntity = new Road(vertexesString, route);
roadList.add(roadEntity);
}
for (KakaoRouteAllResponseDto.Guide guideDto : guides) {
String name = guideDto.getName();
double x = guideDto.getX();
double y = guideDto.getY();
int distance = guideDto.getDistance();
int duration = guideDto.getDuration();
int type = guideDto.getType();
String guidance = guideDto.getGuidance();
int roadIndex = guideDto.getRoadIndex();
Guide guideEntity = new Guide(name, x, y, distance, duration, type, guidance, roadIndex, route);
guideList.add(guideEntity);
}
}
roadRepository.saveAll(roadList);
guideRepository.saveAll(guideList);
}하지만 코드를 바꿨음에도 Hibernate 횟수는 줄지 않았다.
Hibernate에서 saveAll() 메서드를 호출하더라도 내부적으로는 여러 개의 엔티티에 대해 개별적인 INSERT 쿼리를 실행하며, 따라서 saveAll() 메서드를 사용하더라도 여러 번의 개별적인 데이터베이스 호출이 발생한다고 한다.
문제 해결 및 파생 문제 발생2
이를 해결하기위해 Batch를 사용하기로 했다.
Batch 옵션을 키면 다음과 같이 쿼리가 재구성 되어 성능 향상이 일어난다고 한다.

출처: https://velog.io/@rainmaker007/spring-data-jpa-batch-insert-%EC%A0%95%EB%A6%AC
고로 Batch를 활성화 하기 위해 application.properties에 다음과 같은 설정을 했다.
# batch
spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true
spring.jpa.properties.hibernate.generate_statistics=true
spring.jpa.properties.hibernate.jdbc.batch_size=20
spring.jpa.properties.hibernate.order_inserts=true각각의 역할은 아래와 같다.
- hibernate.jdbc.batch_versioned_data=true: 이 설정은 Hibernate가 배치 삽입을 사용할 때 버전 관리된 엔터티에 대해 배치 삽입을 적용하도록 허용하는 옵션입니다. 기본적으로 Hibernate는 버전 관리된 엔터티에 대해서 배치 삽입을 비활성화하고 개별적인 UPDATE 쿼리를 사용합니다. 이 옵션을 활성화하면 버전 관리된 엔터티에 대해서도 배치 삽입을 사용할 수 있습니다.
- hibernate.jdbc.batch_size=20: 이 설정은 한 번의 배치 작업에서 보낼 쿼리의 최대 개수를 지정합니다. 위의 설정에서는 20으로 설정되어 있으므로 Hibernate는 최대 20개의 쿼리를 한 번의 배치 작업으로 묶어 데이터베이스에 전송할 수 있습니다. 배치 크기를 조정하여 데이터베이스와의 트래픽을 최적화할 수 있습니다.
- hibernate.order_inserts=true: 이 설정은 배치 삽입 시에 INSERT 쿼리의 순서를 최적화하는 옵션입니다. 삽입할 엔터티들의 순서를 조정하여 데이터베이스에 쿼리를 보낼 때 레코드들이 물리적으로 연속적인 공간에 저장되도록 최적화합니다. 이를 통해 데이터베이스의 I/O 작업을 최적화할 수 있습니다.
- hibernate.generate_statistics=true: 이 설정은 Hibernate가 통계를 수집하도록 허용하는 옵션입니다. Hibernate의 내부 동작에 대한 통계 정보를 수집하고 이를 모니터링하려면 이 옵션을 활성화할 수 있습니다. 통계 정보는 Hibernate의 성능을 모니터링하고 최적화하는 데 도움을 줄 수 있습니다.
하지만 DB 호출 횟수가 전혀 줄어들지 않았다.
이유를 찾아보니 내 Entity의 형식에 문제가 있었다. 이중 Road.java를 보면 아래와 같은 형식으로 구성되어 있다.
public class Road {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "vertexes", nullable = false, length = 20000)
private String vertexes;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "route_id")
private Route route = new Route();
public Road(String vertexes, Route route) {
this.vertexes = vertexes;
this.route = route;
}
}이 Entity의 문제점은 다음과 같다.
@GeneratedValue(strategy = GenerationType.IDENTITY)를 사용하면 Hibernate는 각 엔터티를 데이터베이스에 삽입한 후에 그 엔터티의 ID를 얻어오기 위해 별도의 SELECT 쿼리를 실행해야 합니다. 이렇게 ID 값을 얻어오는 과정이 배치 삽입의 특성에 반하게 되어 성능상의 이점을 잃게 될 수 있습니다.
또한 @GeneratedValue(strategy = GenerationType.IDENTITY)는 MySQL에서 자동 증가(auto-increment) 칼럼을 사용할 때 사용됩니다. MySQL의 경우, 자동 증가 칼럼을 가진 테이블에 대한 배치 삽입은 일반적으로 지원되지 않습니다.
그래서 IDENTITY를 SEQUENCE로 바꿔봤으나, MySQL에서는 적용하지 않는 방식이라고 한다..
문제 해결
다음 링크를 참고했고, 그 중에서도 JDBC를 이용하는 방법을 채택했다.
https://velog.io/@penrose_15/MySQL%EC%97%90%EC%84%9C-Bulk-Insert%EB%A5%BC-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0-%EC%9C%84%ED%95%9C-%EB%BB%98%EC%A7%93-%EB%AA%A8%EC%9D%8C
JDBC를 채택한 이유는 Table 전략은 비효율적이고, Hibernate 전용 어노테이션은 jpa를 사용하기 위해 ID전략을 바꾸는 방식으로, 예기치 못한 에러를 불러올 수 있다고 한다.
이 중 Hibernate 전용 어노테이션은 추후에 구현해 봐야겠다.
아래는 JDBC를 이용하기 위해 작성한 Repository들 중 하나의 클래스이다.
@Repository
public class RoadJDBCRepository {
private final JdbcTemplate jdbcTemplate;
@Autowired
public RoadJDBCRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public void batchInsert(List<Road> roads) {
String sql = "INSERT INTO road (vertexes, route_id) VALUES (?, ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Road road = roads.get(i);
ps.setString(1, road.getVertexes());
ps.setLong(2, road.getRoute().getId());
}
@Override
public int getBatchSize() {
return roads.size();
}
});
}
}코드를 한줄 한줄 설명해보겠다.
1. private final JdbcTemplate jdbcTemplate:JdbcTemplate은 Spring에서 제공하는 JDBC의 간소화된 버전으로, JDBC의 복잡한 과정을 간단하게 처리할 수 있도록 도와준다.
2. batchInsert 메서드: Road 엔터티의 리스트를 Batch로 데이터베이스에 삽입하는 역할을 한다. JdbcTemplate의 batchUpdate 메서드를 사용하여 SQL 쿼리를 실행하고, BatchPreparedStatementSetter 인터페이스를 구현하여 각 배치에 대한 파라미터 값을 설정한다. 이렇게 함으로써 여러 Road 엔터티를 효율적으로 데이터베이스에 삽입할 수 있다.
3. BatchPreparedStatementSetter: 각 Batch에 대한 파라미터 값 설정을 도와주는 인터페이스
guide에 대해서도 위와같은 형태로 GuideJDBCRepository를 작성했다.
이후 Servicecode에서 repository.saveAll(); 메서드를 JDBCRepository.batchInsert();로 바꿔주면
그동안 저장되는 guide 수와, road 수만큼 발생했던 Hibernate가 아래와 같은 결과로 바꿘걸 볼 수 있다.
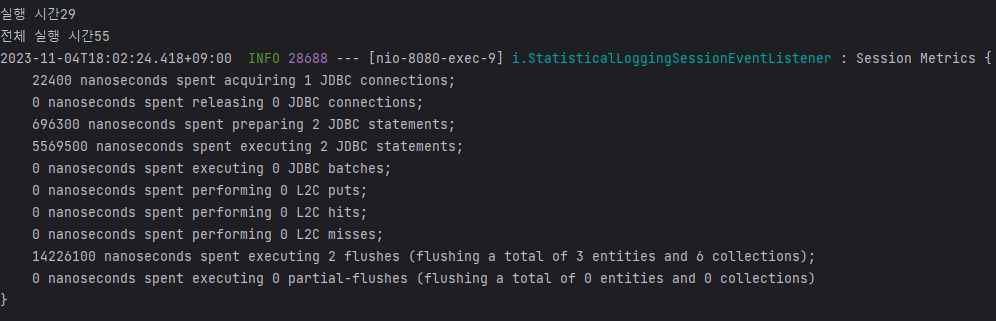
Batch Insert를 사용함으로써, 여러 개의 엔터티를 한 번에 삽입할 수 있게되어 성능이 향상되었다!
하지만 localhost 환경에서는 큰 차이를 보여주지 못한다.
RDS 환경을 이용해서 속도를 측정하고 비교해서 유의미한 결과인지 확인해 봐야겠다.
새로운 시도
첫번째 측정결과 유의미한 차이가 없었다.
물론 이는 측정 오류이다. 아마 환경설정과 네트워크 등의 문제가 겹쳐서 큰 차이가 나지 않는 것으로 나왔을 것이다.
하지만 이를 해결하기 위해 다음 코드를 작성했다.
@Repository
public class RoadEntityManagerRepository {
@PersistenceContext
private EntityManager entityManager;
@Transactional
public void batchInsert(List<Road> roads) {
int batchSize = 50; // 배치 크기를 설정해줍니다.
for (int i = 0; i < roads.size(); i += batchSize) {
List<Road> batch = roads.subList(i, Math.min(i + batchSize, roads.size()));
for (Road road : batch) {
entityManager.persist(road);
}
entityManager.flush();
entityManager.clear();
}
}
}위 코드에 대한 설명은 아래와 같다.
- @PersistenceContext 어노테이션:
- @PersistenceContext 어노테이션은 JPA에서 EntityManager를 주입받기 위해 사용됩니다. 이를 통해 EntityManager를 직접 제어할 수 있게 됩니다.
- batchInsert() 메서드:
- batchInsert() 메서드는 주어진 Road 엔터티 리스트를 받아 일괄 삽입을 수행합니다.
- 먼저, batchSize 변수에 지정된 배치 크기에 따라 리스트를 나누어 처리합니다.
- for 루프를 사용하여 배치 크기만큼의 엔터티를 entityManager.persist() 메서드를 사용하여 영속 상태로 만듭니다. 이렇게 영속 상태로 만들면 JPA가 적절한 시점에 데이터베이스에 삽입됩니다.
- entityManager.flush()는 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영합니다. 이때, 지정된 배치 크기만큼의 엔터티가 데이터베이스에 삽입됩니다.
- entityManager.clear()는 영속성 컨텍스트를 초기화합니다. 이를 통해 영속성 컨텍스트의 메모리를 최적화하고 관리 상태를 초기화합니다. 이는 대량의 데이터를 처리할 때 영속성 컨텍스트의 메모리 부하를 줄이는데 도움이 됩니다.
- 트랜잭션 관리:
- @Transactional 어노테이션은 이 메서드가 트랜잭션 내에서 실행되어야 함을 나타냅니다. 메서드 내의 작업이 모두 성공적으로 완료되면 트랜잭션은 커밋되고, 만약 예외가 발생하면 롤백됩니다.
위 코드를 이용하기 위해서는 Id 자동증가(@GeneratedValue(strategy = GenerationType.IDENTITY))를 이용하지 말아야 한다.
고로 서비스에서 직접 id를 증가시켜야 하고, 이는 DB에서 가장 큰 id값(저장된 값 없으면 null)을 가져와서 1씩 증가시켜 주면 된다. null이라면 1부터 증가시켜주면 된다.
위의 결과 기존의 saveAll()보다는 확연하게 속도가 개선되었다. 하지만 JDBC를 이용한 방식에 비해서는 id를 직접 탐색해서 일일히 증가시켜 줘야 하기 때문에 약간의 속도 차이가 발생했다.
또한 정보 저장시 쿼리실행은 한번뿐이지만 hibernate는 똑같이 여러번 발생하는것을 볼 수 있었는데,
이로 인해 hibernate가 중요한 것이 아니라, 쿼리이용 횟수가 중요하단 것을 알 수 있었다.
즉 hibernate는 직접적으로 DB와 소통하는 것을 보여주는 것이 아니다. 자세한건 아래 설명에 작성하겠다.
Hibernate는 객체-관계 매핑(ORM) 도구로써 자바 객체와 데이터베이스 테이블 간의 매핑을 담당합니다. 이 때문에 Hibernate는 자바 객체의 상태 변화를 추적하고, 필요한 시점에 데이터베이스에 대한 쿼리를 생성하여 실행합니다.
반면, 일반적인 쿼리 실행은 직접 SQL 쿼리를 작성하고 데이터베이스에 직접 전송하여 데이터를 가져오거나 조작하는 방식을 의미합니다. 여기서 주목해야 할 점은 Hibernate가 자바 객체와 데이터베이스 간의 변환 작업을 수행하는 도구이기 때문에, 객체를 영속성 컨텍스트에 저장할 때에는 실제로 쿼리가 데이터베이스에 전달되지 않을 수 있습니다. Hibernate는 영속성 컨텍스트 내에서 객체의 상태를 추적하며, 트랜잭션이 커밋될 때에만 필요한 변경사항을 데이터베이스에 전송합니다.
따라서 Hibernate를 사용하더라도 객체의 상태가 변할 때마다 쿼리가 발생하는 것이 아니라, 트랜잭션이 커밋될 때 한 번의 쿼리 실행으로 여러 변경사항이 반영될 수 있습니다. 이러한 작업은 Hibernate가 영속성 컨텍스트와 트랜잭션을 관리하면서 효율적으로 처리하게 됩니다.
반면에 일반적인 쿼리 실행에서는 필요한 데이터를 가져오거나 조작할 때마다 매번 쿼리가 데이터베이스에 전송되기 때문에, 쿼리 실행 횟수가 많아질수록 성능에 부담이 갈 수 있습니다. 따라서 쿼리 실행 횟수를 최소화하고 효율적으로 데이터베이스와 소통하는 것이 중요합니다.
결론
나름 대량의 데이터가 필요하다는 점과, save 메서드라 캐시를 이용하지 않는다는 점, 그리고 가장 빠른 속도를 가진다는 점에서 JDBC를 이용한 batchInsert() 방식을 채택하기로 했다.
아래는 속도 측정 결과와 각각의 방식의 장단점에 대한 설명이다.
a. 속도 측정 결과(RDS 이용)
EntityManager반 batchInsert반
238, 186, 184, 194, 183, 260, 171, 161, 163, 165
batchInsert
221, 136, 150, 137, 136, 154, 143, 127, 137, 136
saveAll
465, 401, 402, 422, 431, 430, 405, 312, 304, 642
b. 각각의 방식의 장 단점 및 특징
- Spring Data JPA Repository (RoadRepository):
- 기술 설명: Spring Data JPA는 Spring 프레임워크에서 제공하는 JPA 기반의 데이터 액세스 기술입니다. JpaRepository를 확장함으로써 간단한 CRUD 연산과 쿼리 메서드를 사용할 수 있습니다. findMaxId() 메서드는 JPA의 JPQL(Java Persistence Query Language)을 사용하여 최대 ID 값을 찾는 쿼리를 정의하고 있습니다.
- 장점: 간단한 CRUD 작업이나 기본적인 쿼리 작업에 대해 편리하게 사용할 수 있습니다. 개발 생산성이 높고, 복잡한 쿼리를 작성하지 않아도 됩니다.
- 단점: 복잡한 쿼리나 대량의 데이터 일괄 처리에는 제한적일 수 있습니다. 자동 생성되는 쿼리의 성능을 최적화하기 어려울 수 있습니다.
- JPA EntityManager (RoadEntityManagerRepository):
- 기술 설명: EntityManager를 직접 사용하여 JPA 엔터티를 관리하는 방법입니다. 직접 SQL을 작성하지 않고도 대량의 데이터를 일괄 삽입할 수 있습니다. batchInsert() 메서드는 EntityManager를 사용하여 배치 크기에 따라 데이터를 일괄 삽입합니다.
- 장점: 대량의 데이터를 효율적으로 일괄 삽입할 수 있습니다. 일괄 처리로 인한 성능 향상을 기대할 수 있습니다.
- 단점: EntityManager를 직접 다루기 때문에 일부 JPA의 기능(예: 캐시 관리)을 이용하지 못할 수 있습니다. 복잡한 쿼리를 작성하지 않는 것은 장점이 될 수 있지만, 복잡한 로직이 필요한 경우 구현이 어려울 수 있습니다.
- Spring JDBC Template (RoadJDBCRepository):
- 기술 설명: Spring JDBC Template은 JDBC 기반의 데이터 액세스 기술을 제공합니다. 직접 SQL을 작성하여 데이터베이스에 접근할 수 있습니다. batchInsert() 메서드에서는 JDBC Template을 사용하여 대량의 데이터를 일괄 삽입합니다.
- 장점: SQL을 직접 작성하여 세밀한 제어가 가능하며, 대용량 데이터 일괄 처리에 효과적입니다. 복잡한 쿼리나 튜닝이 필요한 경우에 유용합니다.
- 단점: SQL을 직접 작성해야 하므로 개발 생산성이 낮을 수 있습니다. ORM과 비교해 기능이 제한적이며, 일부 기능(예: 캐시 관리)을 사용하지 못할 수 있습니다.
saveAll() vs. batchInsert() 관점에서 비교:
- saveAll(): Spring Data JPA의 내부 메커니즘에 따라 적절한 방법으로 일괄 삽입을 수행합니다. 단일 메서드로 간단하게 사용할 수 있고, 개발자가 신경 써야 할 부분이 적습니다. 대용량 데이터에 대해서도 내부적으로 최적화가 이루어져 있을 수 있습니다.
- batchInsert(): 직접 SQL을 작성하여 데이터를 일괄 삽입하므로 개발자가 세밀한 튜닝이 가능합니다. 대량의 데이터를 효율적으로 처리할 수 있습니다. 그러나 SQL 작성 및 튜닝에 대한 노력이 필요하며, 일부 JPA의 기능을 사용하지 못할 수 있습니다.
'프로젝트 > RanDrive' 카테고리의 다른 글
| 기능 개선(예외처리) (0) | 2023.11.02 |
|---|---|
| 기능 개선(새로운 랜덤 길찾기 알고리즘 프론트 코드 작성) (1) | 2023.11.01 |
| 기능 개선(경유지를 가진 경로 이탈 시 처리) (0) | 2023.11.01 |
| 기능 개선(JMeter) (0) | 2023.10.30 |
| 기능 개선(랜덤 길찾기 알고리즘) (0) | 2023.10.28 |


